Automazione
Generalmente nel testing gli unici due outcomes sono risultato corretto o non corretto e la metrica è una misura della correttezza del programma. Il discriminante delle tecniche di analisi mutazionale è invece il numero di casi di test che forniscono un risultato diverso da quello di \(P\), indipendentemente dalla correttezza (di entrambi).
Come già detto, trovare errori con queste tecniche (specialmente l’HOM) misura quindi il livello di approfondimento dei casi di test e non la correttezza del programma di partenza.
Prescindere dalla correttezza dei risultati ha però un aspetto positivo: per eseguire l’analisi mutazionale non è necessario conoscere il comportamento corretto del programma, eliminando la necessità di un oracolo che ce lo fornisca.
Si può quindi misurare la bontà di un insieme casi di test automatizzando la loro creazione: come già detto precedentemente, occorre però vigilare sulla proliferazione del numero di esecuzioni da effettuare per completare il test – un caso di test dà infatti origine a \(n+1\) esecuzioni, dove \(n\) è il numero di mutanti.
Il seguente diagramma di flusso visualizza quindi l’attività facilmente automatizzabile di analisi mutazionale:
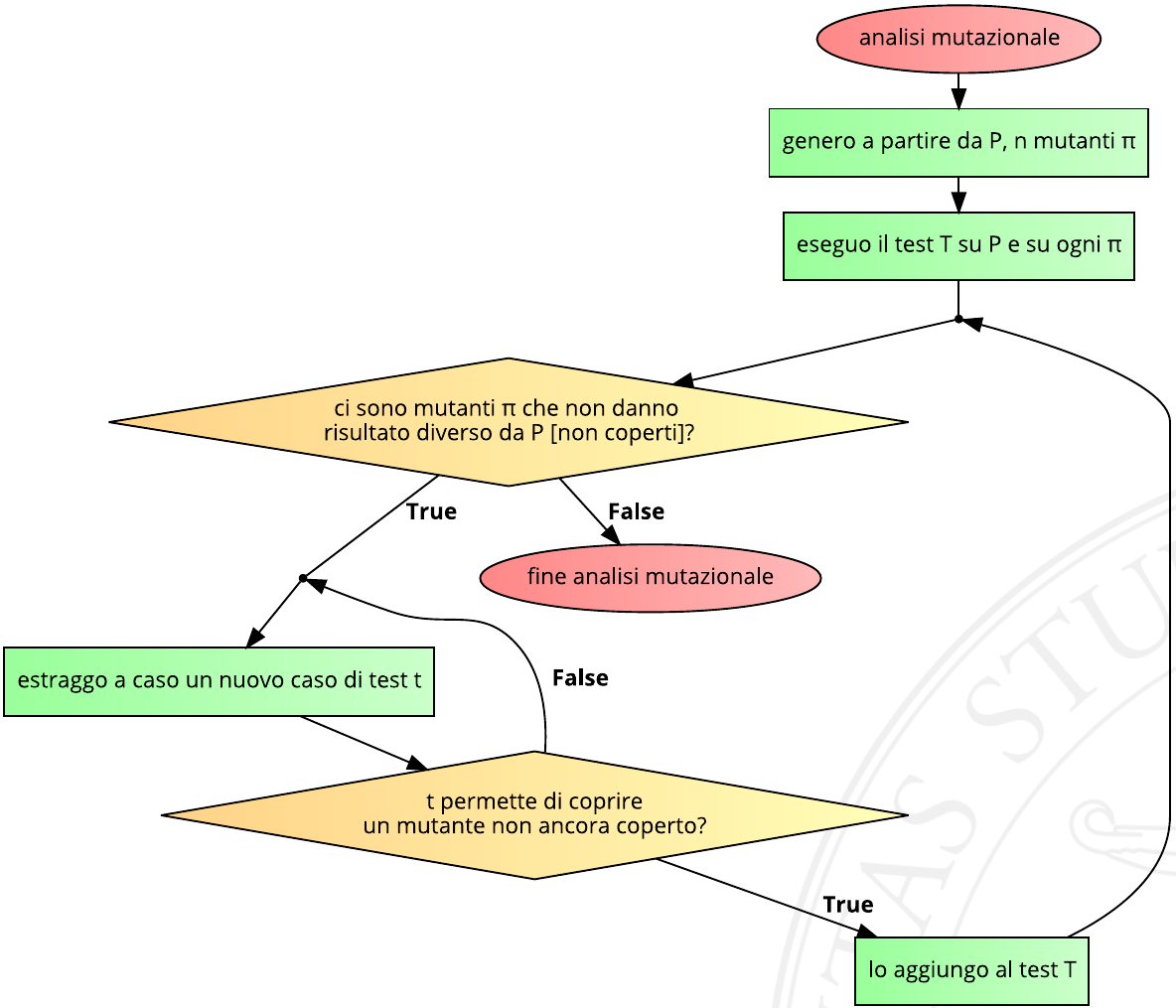
Benché semplice, questo algoritmo non garantisce la terminazione per una serie di motivi:
- quando si estrae un caso di test casuale, c’è sempre il rischio di estrarre sempre lo stesso;
- si potrebbe essere particolarmente sfortunati e non trovare un caso di test utile in tempo breve;
- esistono infinite varianti di programmi funzionalmente identici ma sintatticamente diversi, ovvero che svolgono la stessa funzione anche se sono diversi: una modifica sintattica potrebbe non avere alcun effetto sul funzionamento del programma, come per esempio scambiare
<con<=in un algoritmo di ordinamento. In tal caso, nessun nuovo caso di test permetterebbe di coprire il mutante, in quanto esso restituirebbe sempre lo stesso output del programma originale.
Spesso viene quindi posto un timeout sull’algoritmo dipendente sia dal tempo totale di esecuzione, sia dal numero di casi di test estratti.
Per verificare la validità del test, è necessario controllare il numero di mutanti generati: se questo numero è elevato, il test non era affidabile. In alternativa, è possibile “nascondere” i mutanti, a patto che non sia richiesta una copertura totale. In questo modo, è possibile analizzare programmi che sono funzionalmente uguali ma sintatticamente diversi, al fine di dimostrarne l’equivalenza o scoprire casi in cui essa non è valida.