Modelli incrementali
Un modello incrementale è un particolare modello iterativo in cui nelle iterazioni è inclusa anche la consegna; questo permette di sviluppare il software a poco a poco, rilasciandone di volta in volta parti e componenti che costruiscano incrementalmente il programma finito.
Si noti la differenza tra incrementale e iterativo; si può parlare infatti di:
- implementazione iterativa: dopo aver raccolto le specifiche e aver progettato il sistema, iterativamente sviluppo i componenti, li integro nel prodotto finale, quindi consegno.
- sviluppo incrementale: l’iteratività interessa tutte le fasi, comprese quelle di specifica e realizzazione.
Lo sviluppo incrementale riconosce la criticità della variabilità delle richieste e la integra nel processo. La manutenzione non è quindi più una particolarità ma è vista come normale e perfettamente integrata nel modello; in tal senso, la richiesta di una nuova feature o la correzione di un errore generano gli stessi step di sviluppo.
Modello a fontana
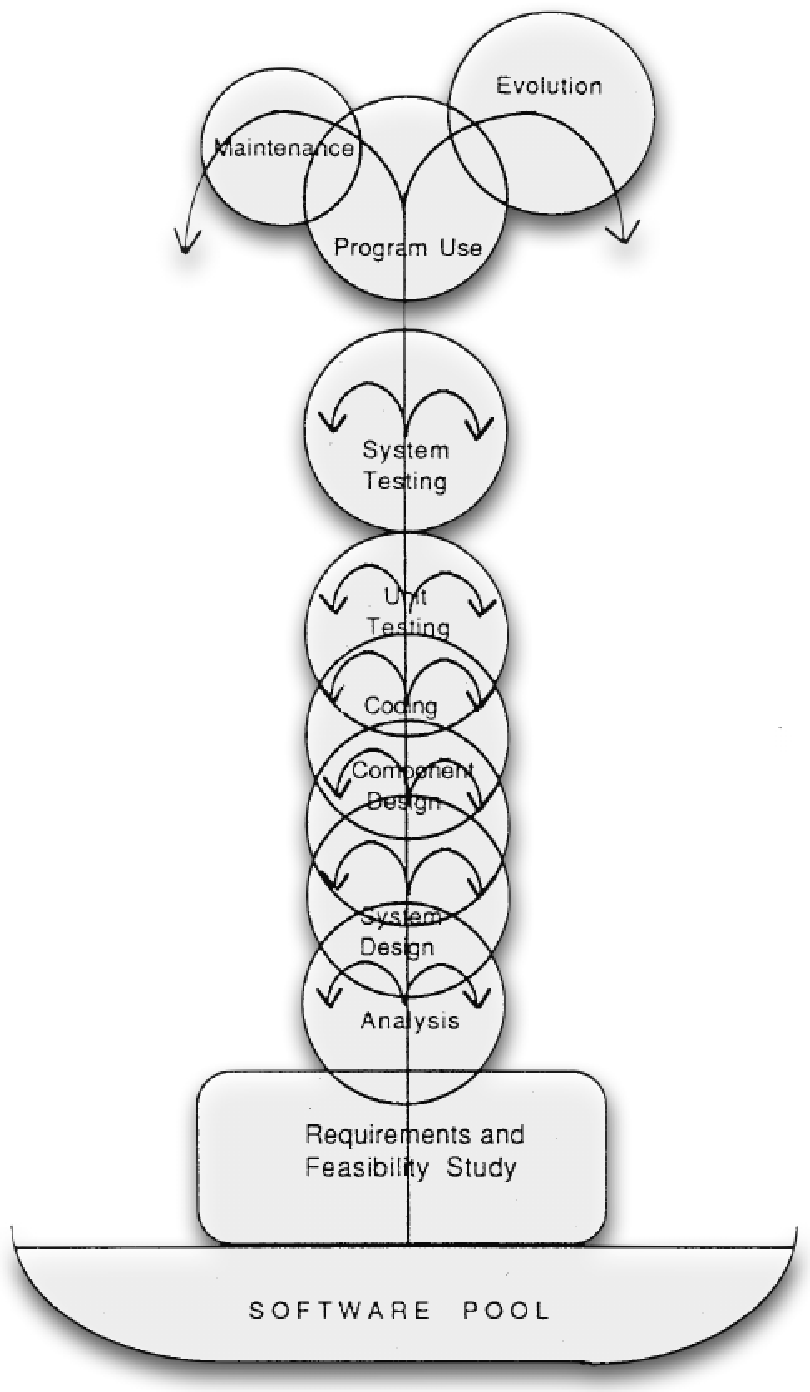
Nel 1993 nasce, in contrapposizione al modello a cascata, il cosiddetto modello a fontana, che amplia il concetto di iterazione permettendo in qualunque momento di tornare alla fase iniziale. Se ci si accorge della presenza di errori si torna all’inizio (software pool) e vengono ricontrollate tutte le fasi precedenti. Ovviamente questo non implica l’eliminazione tutto il lavoro fatto fino a quel momento, quanto piuttosto risolvere l’errore con un approccio che parta innanzitutto dalla modifica dei requisiti (se possibile), delle specifiche e solo dopo del codice, evitando di rattoppare solo quest’ultimo alla bell’e meglio come nel modello code-and-fix.Una volta risolto il problema alla radice si può risalire velocemente attraverso le altre fasi, mantenendo il lavoro già svolto ma controllando che non si siano creati nuovi problemi nel mentre.
Così facendo si mantiene una pulizia del progetto in ogni sua fase, grazie alla continua iterazione di esse ogni volta che si incontra un problema.
Il modello a fontana è inoltre il primo in cui sono previste delle azioni dopo la consegna; dopo l’ultima fase (programma in uso), infatti, si aprono ancora due strade, manutenzione ed evoluzione. La consegna del prodotto non è quindi più l’atto finale, ma solo un altro step del processo, ecco quindi che si aprono le porte ad una visione incrementale dello sviluppo software. Sta proprio in questo la definizione di modello incrementale, ovvero nell’includere la consegna del progetto all’interno delle iterazioni.
Anche qui vengono perdute le garanzie sui tempi di sviluppo; una volta ritornati alla fase iniziale per risolvere un problema non c’è la certezza di riuscire a raggiungere il punto da cui si è partiti, questo perchè è possibile imbattersi in altri errori nelle le fasi intermedie, costringendo un’ietazione continua per risolvere i diversi problemi. In questo modo il software perde completamente il concetto di linearità e sarà impossibile prevederne i tempi di sviluppo, data la continua possiblità di evoluzione e manutenzione.
I problemi dei modelli incrementali
Come già detto nessun modello è perfetto, e anche i modelli incrementali soffrono di alcuni problemi.
Viene innanzitutto complicato il lavoro di planning; bisogna pianificare tutte le iterazioni e lo stato di avanzamento è meno visibile; inoltre, la ripetizione di alcune fasi richiede di avere sempre sul posto gli esperti in grado di eseguirle. Ad ogni iterazione, poi, è necessario revisionare ciò che è stato fatto, in un processo che potrebbe non convergere mai a una versione finale, infatti è possibile che in una iterazione venga tolta una parte perchè complica l’avanzamento del progetto, oppure che il cliente cambi le sue richieste.
Ma cosa è un’iterazione, e quanto dura? Tagliare verticalmente sulle funzionalità non è infatti facile, soprattutto considerando che quando viene consegnato il prodotto esso dev’essere funzionante e progettato per consentire l’aggiunta di nuove features in modo semplice. Ci sono dunque diversi rischi:
- voler aggiungere troppe funzionalità nella prima iterazione;
- overhead dovuto a troppe iterazioni;
- avere un eccessivo overlapping tra le iterazioni, quindi mancanza di tempo per recepire il feedback dell’utente (es. Microsoft Office 2020 e 2019 vengono sviluppati contemporaneamente).
Paper a riguardo: From Waterfall to Iterative Development – A Challenging Transition for Project Managers
Pinball Life-Cycle
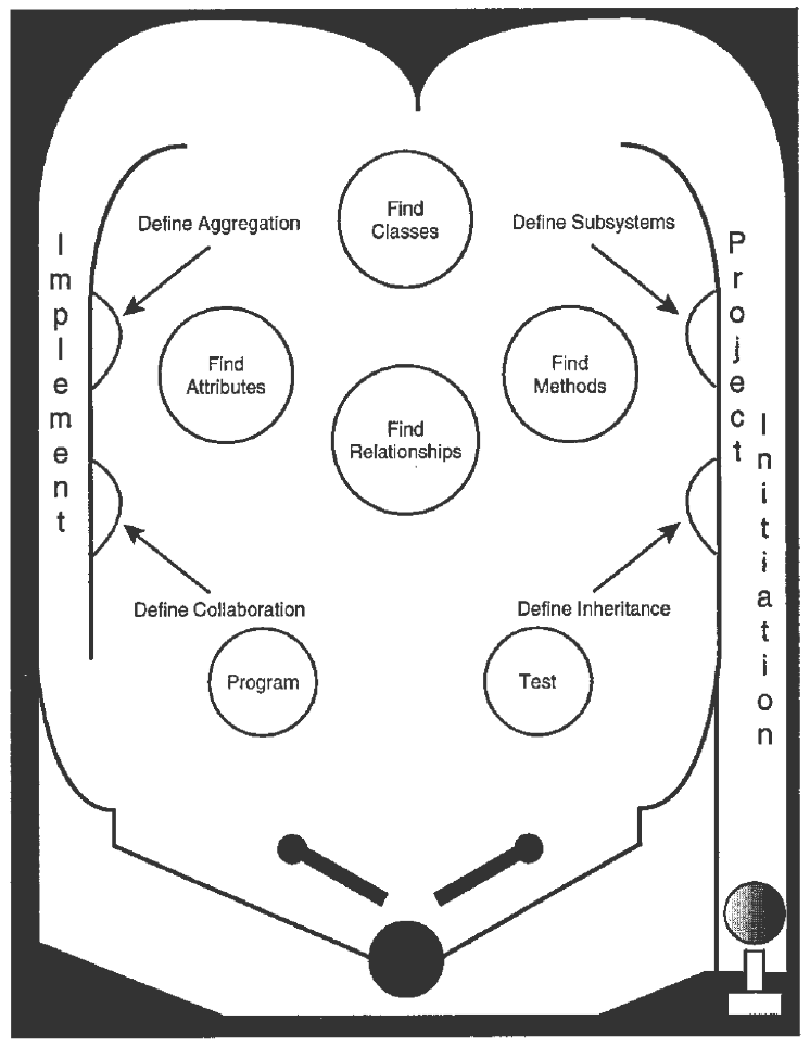
Il “modello meme” del Pinball Life-Cycle, creato da Ambler come critica ai modelli incrementali, evidenziando come l’ordine in cui faccio le attività è casuale, incoltrollabile. Qualunque passo è possibile dopo qualunque altro, e non si possono imporre vincoli temporal, di conseguenza il processo è non misurabile.
Si tratta ovviamente di una visione eccessivamente pessimistica, ma spesso nelle aziende non specializzate l’iter di sviluppo assomiglia effettivamente a questo.
Modelli trasformazionali
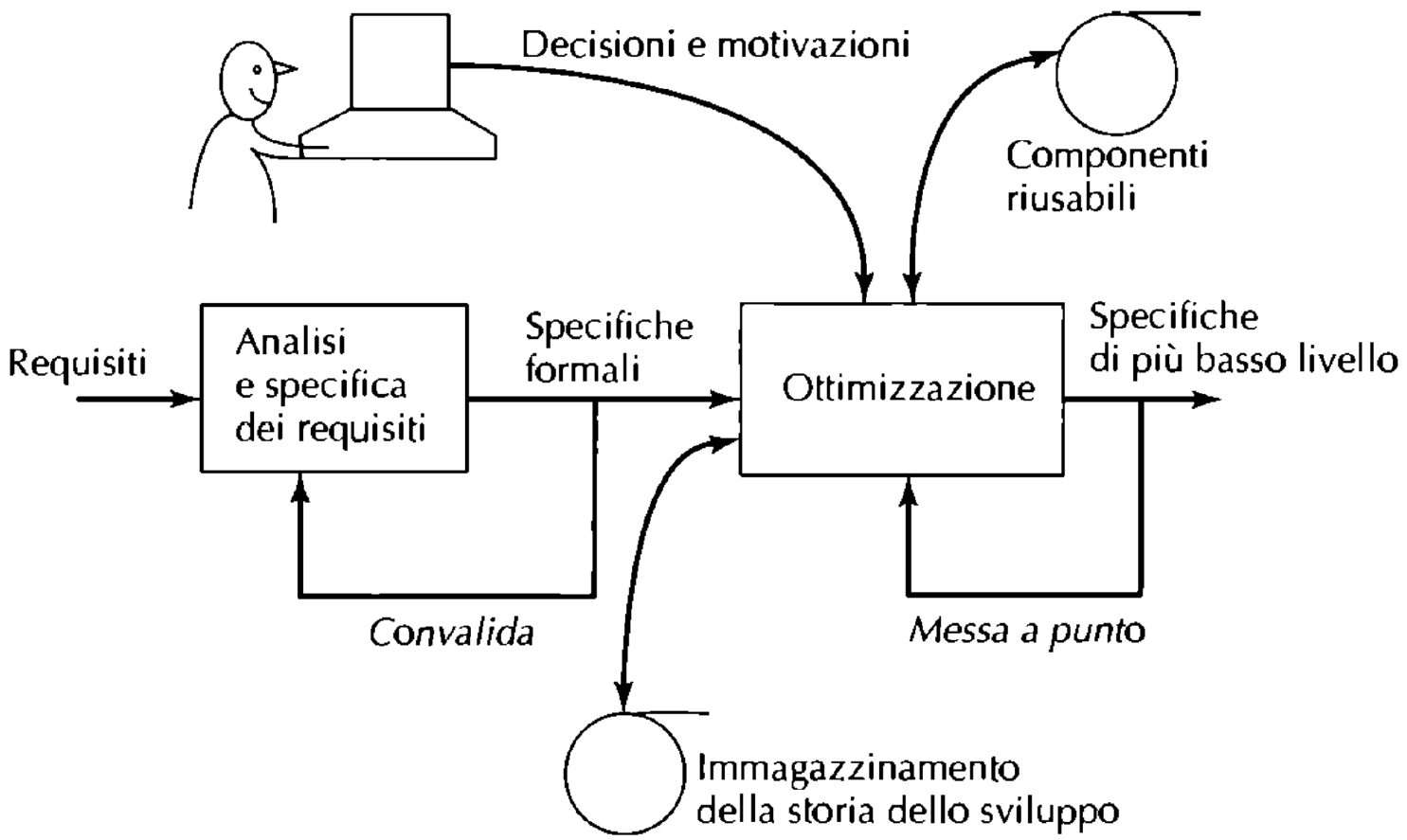
Diametralmente opposti all’incubo del Pinball Life-Cycle troviamo i modelli trasformazionali, tali modelli pretendono infatti di controllare tutti i passi e i procedimenti in modo formale e di estremizzare il numero di incrementi.
Partendo dai requisiti scritti in linguaggio informale, tali modelli procedono tramite una sequenza di passi di trasformazione dimostrabili tutti formalmente fino ad arrivare alla versione finale. Essi si basano infatti sull’idea che se le specifiche sono corrette e i passi di trasformazione sono dimostrati allora ottengo un programma corretto, ovvero sicuramente aderente alle specifiche di cui sopra. Inoltre, la presenza di una storia delle trasformazioni applicate permette un rudimentale versioning, con la possibilità di tornare indietro a uno stato precedente del progetto semplicemente annullando le ultime trasformazioni fatte.
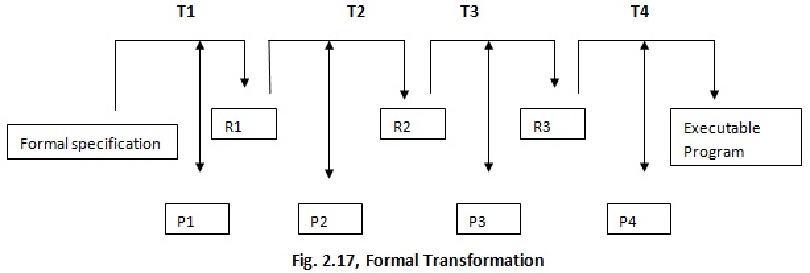
Ad ogni passo si ottiene quindi un protitipo che differisce dal prodotto finale per efficienza e completezza, ma che è possibile trasformare in un altro più efficiente e corretto. Non si tratta tuttavia di un processo totalmente automatico, anzi, ad ogni passo di “ottimizzazione” (ovvero applicazione di una trasformazione) è richiesto l’intervento di un decisore umano che scelga che cosa ottimizzare.
Viene quindi introdotto il concetto di prova formale di correttezza delle trasformazioni applicate; a causa di questo approccio molto rigido, questi modelli sono applicati nella realtà quasi solo negli ambienti di ricerca oppure in progetti che includono sia hardware che software, come ad esempio lo sviluppo di processori.
Metamodello a spirale
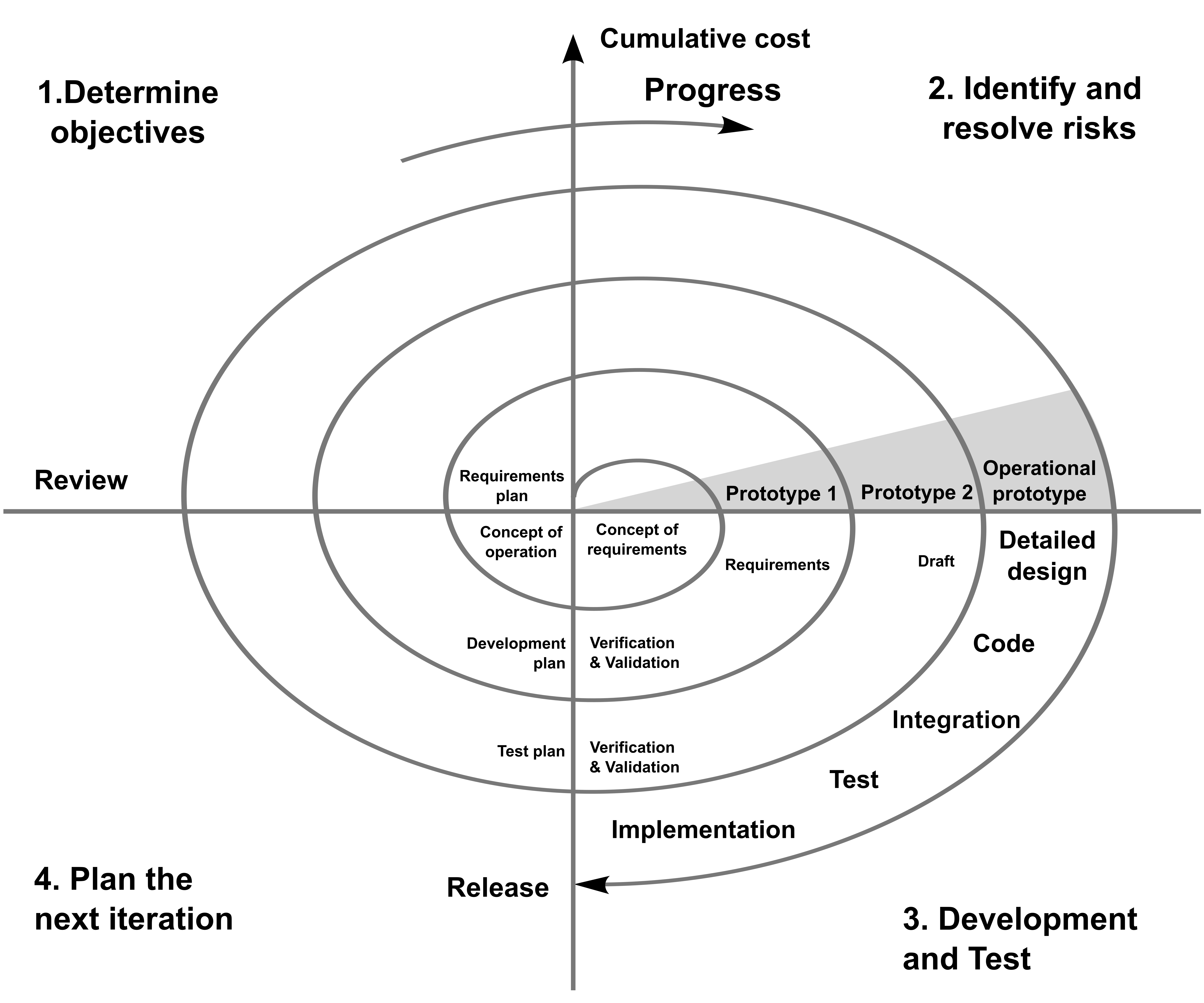
Introduciamo ora un metamodello, ovvero un modello che ci permette di rappresentare e discutere di altri modelli (una sorta di framework).
Nel metamodello a spirale l’attenzione è posta sui rischi (risk_based), ovvero sulla possibilità che qualcosa vada male (decisamente probabile nell’ambiente di sviluppo software). Per questo motivo il modello è di tipo incrementale e pone l’accento sul fatto che non abbia senso fare lo studio di fattibilità una sola volta, ma ad ogni iterazione serva una decisione. Le fasi generali sono dunque:
- Determinazione di obiettivi, alternative e vincoli
- Valutazione alternative, identificazione rischi (decido se ha senso andare avanti)
- Sviluppo e verifica
- Pianificazione della prossima iterazione
Nella figura il raggio della spirale indica i costi, che ad ogni iterazione aumentano fisiologicamente. Questo metamodello porterà alla possiblità di scegliere la via iterativa o quella incrementale, in base alle esigenze del progetto.
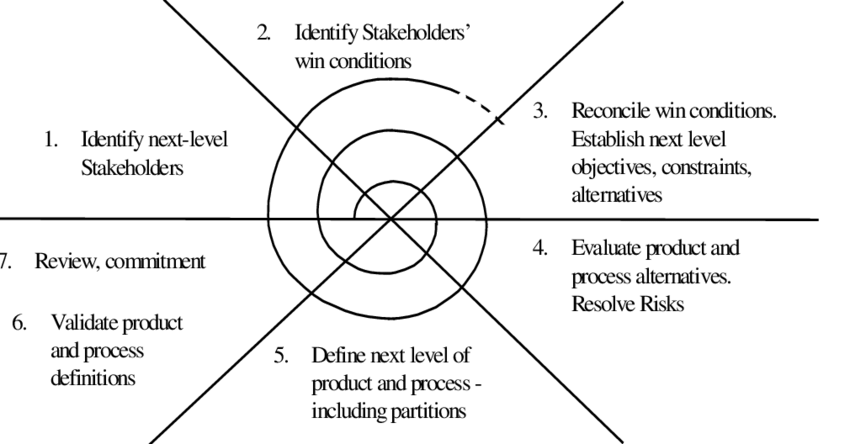
Variante “win-win”
Esiste una variante del modello a spirale che fa notare come i rischi ad ogni fase non sono solo rischi tecnologici ma anche contrattuali con il cliente. Ad ogni iterazione bisogna dunque trovare con esso un punto di equilibrio (win-win) in cui entrambi le parti “vincono” (o hanno l’illusione di aver vinto), così da far convergere tutti su un obiettivo comune.
Modello COTS (Component Off The Shelf)
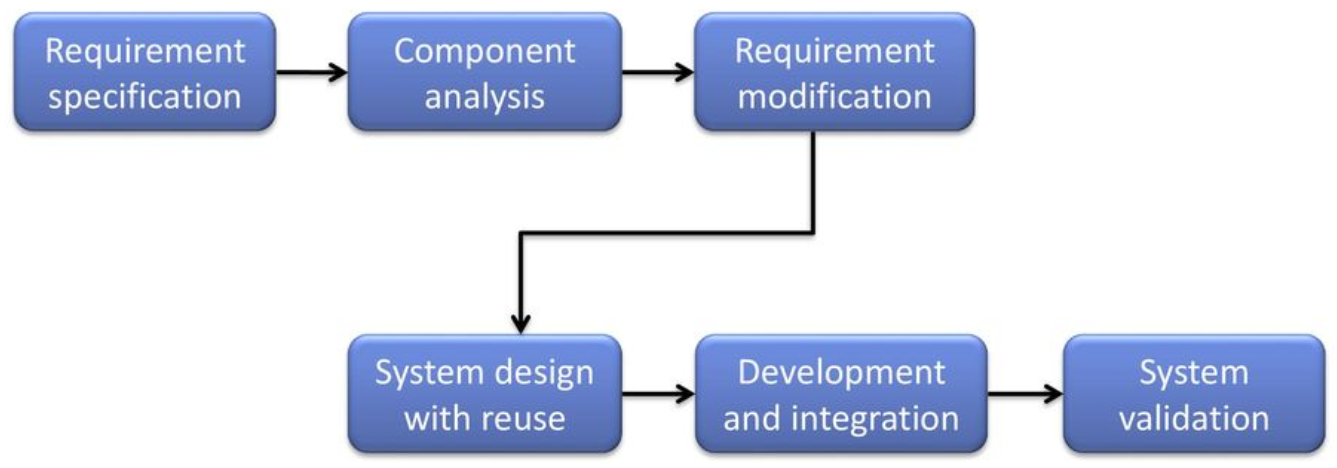
Vediamo infine un modello che si concentra molto sulla riusabilità; si parte dalla disponibilità interna o sul mercato di moduli preesistenti sui quali basare il sistema, e che è dunque necessario solo integrare tra di loro.
Non si creda che si tratti di un approccio facile, questo modello di design necessita un dialogo tra componenti che non necessariamente comunicano già nel modo voluto.
Si tratta tuttavia di un modello di sviluppo diverso perché richiede attività diverse. In particolare:
- Analisi dei requisiti
- Analisi dei componenti: prima di progettare considero la disponibilità di componenti che implementano una parte o tutte le funzionalità richieste;
- Modifica dei requisiti: stabilisco se il cliente è disposto ad accettare un cambiamento nei requisiti necessario per utilizzare un componente particolare;
- Progetto del sistema col riuso di componenti: occorre progettare il sistema per far interagire componenti che non necessariamente sono stati progettati per farlo;
- Sviluppo e integrazione;
- Verifica del sistema.
I lati positivi di questo approccio risiedono nel fatto che non bisogna sviluppare tutto da zero ma vengono utilizzate delle componenti già esistenti. D’altra parte, nel caso in cui il numero di componenti sia troppo elevato, il lavoro di adattamento sarà molto complesso, e le funzionalità non necessarie di quest’ultime andranno ad inficiare sul risultato finale del progetto, diminuendone ad esempio l’efficienza (se in un software vengono importate molte librerie di cui si utilizzano solo poche funzione si avrà una perdita di efficienza in termini di tempo e spazio occupato).
Sviluppi futuri
Oggi lo sviluppo delle intelligenze artificiali sta facendo enormi passi in avanti, basti vedere lo sviluppo di strumenti come ChatGPT o Copilot, che stanno rivoluzionando il mondo dell’informatica. Negli anni a venire sicuramente giocheranno un ruolo importante anche nella gestione del processo produttivo di un software, ma ad oggi non sono ancora utilizzate in ambito aziendale.