Modelli sequenziali
Il modo più semplice e immediato di organizzare le fasi del ciclo di vita di un software è sicuramente quello sequenziale: i vari passaggi vengono posti in un ordine prestabilito e vengono attraversati uno alla volta uno dopo l’altro. Da questa idea nascono i cosiddetti modelli sequenziali, di cui il più famoso è certamente il modello a cascata.
Modello a cascata
Caratteristiche e punti di forza
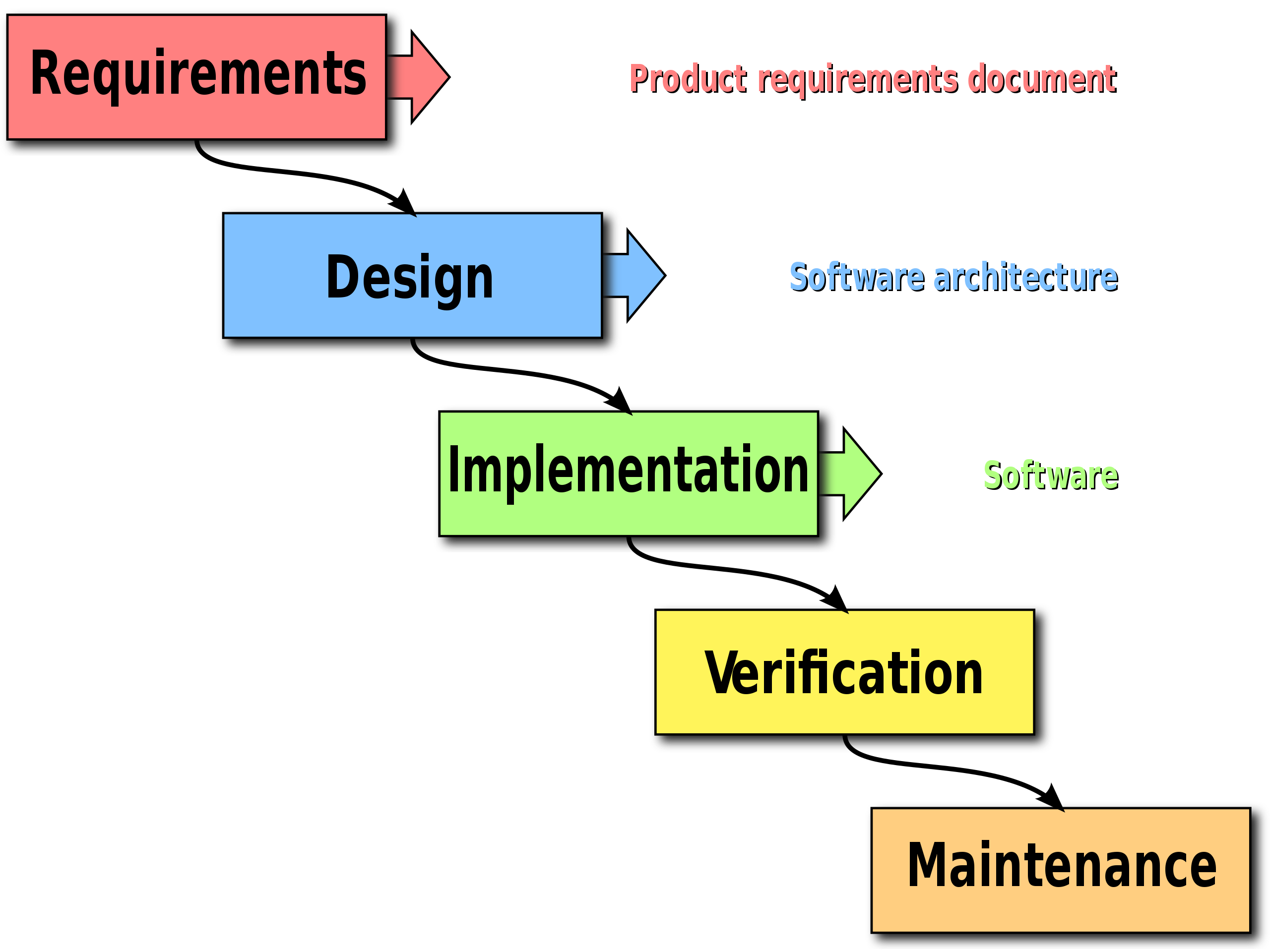
Nato negli anni ’50 ma diventato famoso solo negli anni ’70 grazie allo sviluppo di un grosso software per la difesa area chiamato SAGE (Semi-Automated Ground Environment), il modello a cascata organizza le fasi in una serie di step sequenziali: fatto uno si passa al successivo fino ad arrivare alla fine, come in una sorta di catena di montaggio. Viene infatti forzata una progressione lineare da una fase alla successiva; non è previsto in questo modello tornare indietro a uno step precedente.
Sebbene varino molto da processo a processo, la maggior parte dei processi che segue il modello a cascata include almeno le seguenti fasi organizzate in quest’ordine:
- Requisiti
- Progetto
- Codifica
- Testing
- Prodotto
Ognuno di tali step produce un output, detto semilavorato, che è dato come input allo step successivo. In virtù dell’affidamento su tali semilavorati intermedi il modello a cascata si dice document-based: tra una fase e l’altra si crea infatti un documento che è il mezzo di trasmissione dell’informazione. Questo aspetto permette una buona separazione dei compiti tra i vari dipendenti che lavorano al progetto: ognuno è infatti specializzato in una singola fase e una volta prodotto il documento utile ad avviare la fase successiva il suo coinvolgimento nel progetto non è più necessario ed esso può essere assegnato ad altri lavori. Da tutto ciò è facile evincere che questo modello ha introdotto un certo rigore che fino allora non si era ancora visto nel mondo dello sviluppo software, dando importanza anche alla documentazione del lavoro.
La linearità del modello rende inoltre possibile pianificare i tempi accuratamente e monitorare semplicemente lo stato di avanzamento in ogni fase: è infatti sufficiente stimare la durata di ogni fase per ottenere una stima del tempo di completamento dell’intero progetto. Si tratta però di una stima a senso unico: una volta finita una fase non è possibile ridurre il tempo speso, e in caso di inconvenienti l’unica opzione è cercare di assorbire il ritardo.
Criticità
Sebbene il modello a cascata abbia il grande pregio di aver posto l’attenzione sulla comunicazione tra gli elementi del progetto in un momento storico in cui il modello di sviluppo più diffuso era di tipo code-and-fix, esso soffre di numerose criticità.
In primo luogo il modello non prevede una fase di manutenzione del software prodotto: esso assume di non dover apportare modifiche al progetto dopo averlo consegnato, e impedisce dunque di “tornare indietro” in alcun modo. Ovviamente questa assunzione è un’illusione smentita nella quasi totalità nei casi: qualunque software è destinato ad evolvere, e più un software viene usato più cambia. Una volta finito lo sviluppo ciò che si può fare è rilasciare al più piccole patch, che tuttavia non fanno altro che disallineare la documentazione prodotta precedentemente con il software reale.
Il modello soffre inoltre di una generale rigidità, che mal si sposa con la flessibilità naturalmente richiesta dall’ambiente di sviluppo software. In particolare, l’impossibilità di tornare indietro implica un congelamento dei sottoprodotti: una volta prodotto un semilavorato esso è fisso e non può essere modificato; questo è particolarmente critico per le stime e specifiche fatte durante le prime fasi, che sono fisiologicamente le più incerte.
Infine, il modello a cascata adotta un approccio volto alla monoliticità: tutta la pianificazione è orientata ad un singolo rilascio, e l’eventuale manutenzione può essere fatta solo sul codice. Inutile dire che si tratta di una visione fallace, in quanto come già detto più volte il software è destinato ad essere modificato e ad evolvere.
Who’s Afraid of The Big Bad Waterfall?
LIBRO: The Leprechauns of Software Engineeering di Laurent Bossavit.
In realtà, il modello a cascata non è mai stato veramente elogiato, ma è sempre stato utilizzato come paragone negativo per proporre altri modelli o variazioni. Nel corso del tempo la sua presentazione è stata erroneamente attribuita al paper “Managing the development of large software systems: concepts and techniques” di W.W. Royce, di cui veniva citata solo la prima figura: Royce stava a dire il vero presentando quel modello per descrivere la sua esperienza nello sviluppo software, per poi proporre altri concetti più moderni (come lo sviluppo incrementale) che non sono però mai stati colti dalla comunità scientifica.
Anche noi utilizziamo il modello a cascata solo come paragone negativo, e in generale nell’ambiente di sviluppo software esso non è più applicato alla lettera. Alcuni suoi aspetti si sono però mantenuti come linee guida generali (es. l’ordine delle fasi); è infatti bene chiarire subito che esistono due tipi di modelli:
- prescrittivi: forniscono delle indicazioni precise da seguire per svolgere un processo;
- descrittivi: colgono certi aspetti e caratteristiche di particolari processi esistenti, ma non obbligano a seguirli in modo rigoroso.
Tutti i modelli visti per ora ricadono perlopiù nell’ambito descrittivo, mentre i modelli AGILE che vedremo più avanti tendono ad essere più di tipo prescrittivo.
Riassunto pro e contro
| Pro | Contro |
|---|---|
|
|
Modello a V (denti di pesce cane)
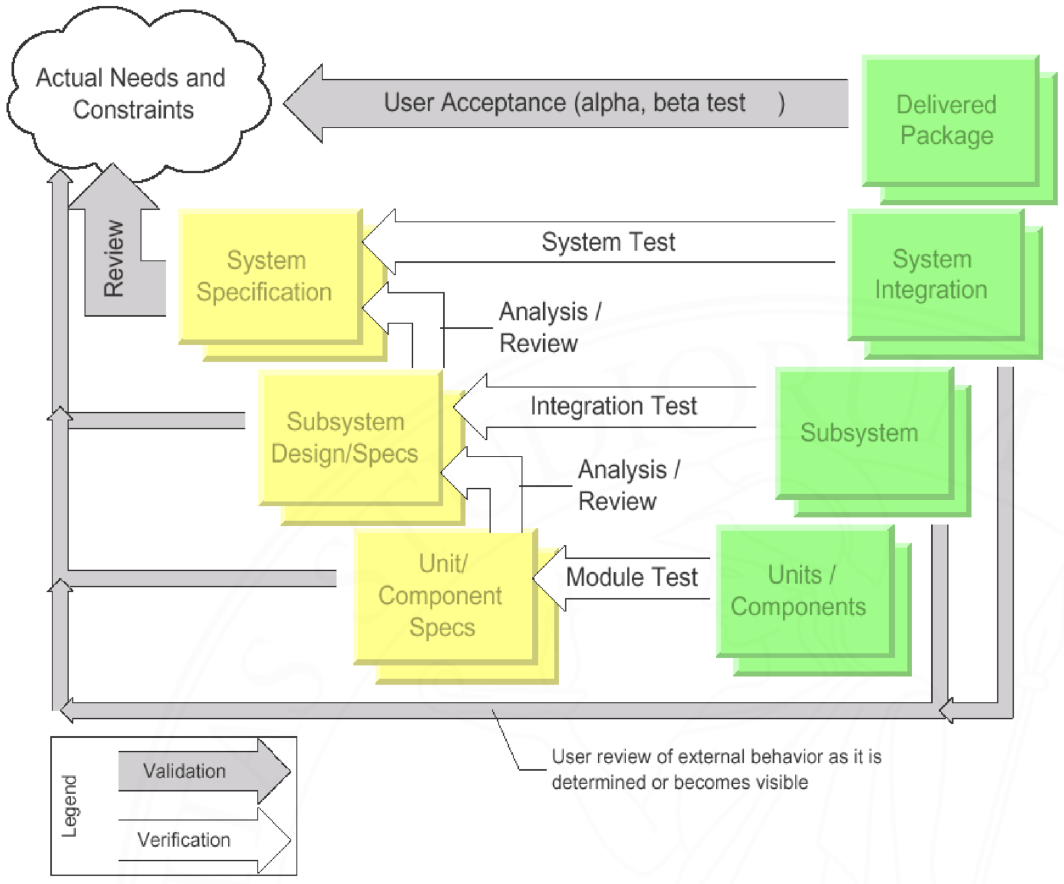
Dal modello a cascata nascono poi numerose varianti che cercano di risolverne i vari problemi: tra queste spicca per rilevanza il modello a V, che introduce fondamentalmente una più estesa fase di testing.
Nonostante sia ancora un modello sequenziale come il modello a cascata, nel modello a V vengono infatti evidenziati nuovi legami tra le fasi di sviluppo, che corrispondono alle attività di verifica e convalida: alla fine di ogni fase si verifica che il semilavorato ottenuto rispetti la specifica espressa dalla fase precedente, e inoltre si richiede la convalida del fatto che esso sia in linea con i veri vincoli e necessità del cliente. Come si vede, questo modello pone l’accento sul rapporto con il cliente, che viene continuamente coinvolto con la richiesta di feedback su ciascun sottoprodotto generato. Inoltre, ogni fase include delle ‘frecce implicite’ dirette verso se stessa, indicando la necessità di una verifica per garantire la coerenza e la logica del risultato prodotto.
Volendo formalizzare, le due nuove attività introdotte sono dunque:
- verifica (freccie bianche): controlla la correttezza rispetto alla descrizione formale delle specifiche, (in queste verifiche non è coinvolto il cliente);
- validazione (freccie grigie): controlla la compatabilità del sistema con le esigenze del cliente tramite feedback continuo.